
2025年4月18日、メルカリが生成AIを用いた新たな社内向けのデータ分析ツール「Socrates(ソクラテス)」をローンチ。リリース後すぐ、1週間で約500名の社員が利用するなど社内でも注目を集めるこのツールは、構想からたったの1ヶ月で完成しました。
そこで今回は、“生成AI頑張るぞ担当”のハヤカワ五味(@gomichan)がファシリテーターを務め、プロジェクトを主導したメンバーから開発の裏側と、Socratesの可能性について話を聞くことに。話を聞いたのは、BI(Business intelligence)Productチームのマネージャーを務める小林健太郎(@kobaken)、エンジニアの山田直史(@na0)、データプロダクト全体を統括するディレクターの飯田修一(@Shuichi)です。
Socratesの話をきっかけに広がった開発や組織づくりの話題にもご注目ください。
この記事に登場する人
-

小林健太郎(Kentaro Kobayashi)
2019年に新卒入社した企業で国内外のサービスでデータマネジメントに従事した後、2023年にメルカリへ入社。A/Bテスト基盤の改善やBasic Tablesプロジェクトのリードを経て現職。現在はデータ組織のAI Native化の活動も推進している。東京大学経済学研究科卒(修士)。
-

山田直史(Naofumi Yamada)
ソフトウェアエンジニア、アナリスト、データエンジニアとして計3社で経験を積んだ後、2022年にメルカリへ入社。メルカリでは古くなったデータのマイグレーションやBasic Tables開発などに携わり、現在はAIエージェント Socrates の開発推進を担う。
-

飯田修一(Shuichi Iida)
DeNA, DeNA San Francisco を経て 2014年にメルカリ入社。 メルカリUSにて米国でのメルカリの立ち上げに参画した後、2020年に日本に帰国しメルカリJPに転籍。 現在はデータプロダクトチーム全体の責任者を務める。東京大学数理科学研究科卒(博士)。シリコンバレー在住歴は計7年半。
自律的なデータ分析と仮説導出を行うAgentic AI
ーSocratesのローンチおめでとうございます!まず、Socratesの機能について教えてください。
kobaken:Socratesは、メルカリのデータに関する分析を会話形式で実行できるツールです。SQLやメルカリのデータの専門的知見がなくとも、データの可視化からトレンドの把握と深堀り、仮説の導出、分析レポートの作成までを一気通貫で簡単に実行することができます。

ー社内のデータ分析ツールは他にもありますね。それらとSocratesを比較して、どのような違いがあるのでしょうか?
na0:従来の社内ツールは、LLMに単一の応答をしてもらう前提でつくられていました。メルカリの月間利用者数を求めるSQLを書いてほしいと頼めば、頼んだことを1ステップでできる範囲で応答してくれます。
一方、SocratesはAIエージェントとして実装され、これらのツールと比べて探索範囲が広く設計されています。1ステップの応答に留まらず、利用者の課題意識から調査を進め、データを収集、仮説を出して、その仮説を前提にさらなる調査を行うことができます。
ーそれは、特定のタスクをこなす「AIエージェント」というより、目的に向かって自律的に駆動する「エージェンティックAI」の考え方に近いと思いますが、そのための技術的な工夫はありますか?
na0:Socratesに対してスコープの大きなゴールプロンプトとツールを提供する一方で、最低限のガードレール(制御の仕組み)だけを設けるようにしました。Socratesの利用状況を用いて、分析してプロンプトとガードレールを改善するサイクルを回しながら、利用者の期待するルートにたどり着く確率を高めるようにしています。

ーあえてハルシネーションを制御しすぎず、自由な分析や仮説導出ができることのほうに重きをおいていると。
na0:多様なハルシネーション全てを防ごうとすると、Socratesの思考範囲を狭めることになってしまうかもしれません。初期の開発では、ハルシネーションを抑制することよりもハルシネーションを発見できることに重きをおいており、ハルシネーションが発生した時に利用者の行動を促すようにしています。実行したクエリや処理の過程を、利用者がUI上で観察、検証できるように作っています。例えば、クエリを実行していないのに「クエリを実行しました」と Socrates が言ってきた場合にも、UIを見れば利用者や検証担当者が分かるようになっています。

ー強固なガードレールによって、LLMの回答が人間の想定を超えられなくなるという話はよく聞きます。今回は、LLMの限界と伸び代を正確に捉えた上で、Socratesの力を一番引き出せるような設計になっていると感じました。
データ基盤の整備と、遊軍チームによる迅速な立ち上げ
ー続いて、開発背景について聞かせてください。なぜ、このタイミングで立ち上げたんでしょうか?
kobaken:今年、メルカリのバリューに「Move Fast」が加わり、意思決定とその実行の素早さをより意識するようになりました。そのためには定量的なサポートとしてデータが欠かせないのですが、複雑な分析にはSQLのスキルや分析設計に関する知見が必要です。また、複雑な分析ニーズにはデータアナリストのサポートが一定必要だったので、チームのリソースが逼迫していると意思決定のスピードが鈍化してしまうという懸念がありました。
BI Productチームでは、昨年からそのような課題を解消するためのアプローチを試行錯誤していました。LLMを活用したクエリ生成は最たる例ですが、精度の面でなかなか実用化にはいたらなかった。そうしたなか、LLMのモデルのアップデートも背景にあり、メタデータの整備を並行しさえすればある程度許容可能な品質のクエリを生成できる兆しが見えたため、3月の中旬から本格的な開発をスタートしました。
ーもともとの構想に技術が追いついたんですね。ローンチまでにはどのくらいかかりましたか?
kobaken:だいたい1ヶ月です。開発の議論が始まったのが3月初旬で、中旬にはプロトタイプをリリースして社内のメンバーからフィードバックを集め始め、改善しながら4月半ばに正式にローンチしました。
ーなぜそんなに素早く立ち上げられたんですか?
Shuichi:ひとつの要因は、BI ProductチームがProduct Div配下にありながら、独立した遊軍のように動けたことです。BI Productチームは、企画・設計・開発・社内マーケティングまで全て出来る組織なので、そもそもチームを超えた連携のために行う調整が必要なく、チーム内で開発を進めることができました。

na0:Socratesの開発を進めたいと相談する@Shuichiさんとのキックオフミーティングに向けて、Webページ上で動作するモックをつくっていきました。その場で実際に参加者のPCから大まかな挙動や精度を把握してもらったことで、よりスムーズに開発スタートの決定ができたと思います。私がこの話をもらった翌々日にモックを作っていったのですが、LLM自体の進化やエージェントを開発するためのフレームワークの成熟は、モックを早く作ることができた理由として大きかったですね。
ー@Shuichiはモックを見ての所感はいかがでした?
Shuichi:これまでもLLMを活用した分析ツールの構築を試行錯誤してきましたが、技術的に実用化できる精度ではありませんでした。ですが今回はミーティングに持ってきてもらったモックの時点で、精度が一定クオリティに達していると感じたので、すぐにプロジェクトをスタートすることにしました。
kobaken:もうひとつ、Socratesの構想前からメルカリ内のデータ整備を進めていたことも要因として大きかったと思います。弊社ではMarketplaceに関する分析の効率化を目的に「Basic Tables」という品質の高い中間テーブル群を整備していて、Socratesが参照できるデータをあえてその中のデータに制限することで、初期段階から品質の高い応答を実現できました。
ーこれまでの積み重ねが資産として活きたと。開発サイドの@na0からみて、今回のプロジェクトが素早く進んだ要因はありますか?
na0:スタート時点でSocratesの目指す夢が言語化され、プロジェクトに携わるメンバーが共通認識を持てていたのが大きかったと思います。
早々にモックに着手したのは、夢をまずは現実にしようという思いからです。話し合って夢を広げていくよりも、最低限動くプロダクトを用意して、他のメンバーに使ってもらいながら意見を聞く。その方が具体的な改善点などが見えやすくなります。”まず動くものを作る”は、リーン(無駄がなく、均整が取れた状態)なAI開発にとても大事だと思います。
その後は、アナリストからフィードバックをもらって改善を実施し、改善のたびに公開範囲を拡大して、利用者拡大と機能の拡張を進め、良いフィードバックの循環に入ることができました。周囲に多くの前向きな期待があったのもよかったです。
ー精度を高めるために“プロンプトへのフィードバック”を採用している理由が気になりました。中には「LLMが賢くなり、次第にプロンプトエンジニアリングの重要性は低下していく」という考えもありますよね。ただ、私自身は、人間の期待以上の回答を引き出すためには、逆にプロンプトが重要ではないかとも思っているんです。プロンプトエンジニアリングについては、どう考えていますか?
na0:Socratesは利用状況を分析し、対処できなかった問題について、プロンプトとツールの改善を定期的に行っています。LLMの回答の精度を高めるうえで、プロンプトはまだまだ有効だと思います。技巧的なプロンプトエンジニアリングの重要性は下がりましたが、状況に応じた行動をLLMに理解してもらうことは引き続き重要です。
具体的な課題としてSocratesに社内用語を伝える場合に、単純にプロンプトに追加する方法と、用語集ツールを実装していつ使うべきか伝える方法があります。誰が使っても同じ意味の社内用語は最初のプロンプトに含めますが、使っている組織によって意味が異なるような用語はプロンプトではなく用語集ツールをうまく使ってもらう必要があります。そういう意味では、プロンプトを含めた全体の設計の重要性が高まっていると思います。
kobaken:特にリリースまでの期間はコアな機能の実装に集中し、運用ルールやガードレールの整備は利用状況に合わせて順次設定するように意識していたのですが、そういう意味でも、プロンプトの改善により開発をしていくというアプローチは、今回のプロジェクトと相性が良かったと思います。
外部向けプロダクトのような本気の社内浸透施策
ー素早く立ち上がったSocratesは、ローンチからかなりの反響を得たと聞いています。現在、どれくらいのメンバーが使っていますか?
kobaken:1週間に約500人の方が使ってくれています。他の全社向けダッシュボードの週間ユーザー数が100人くらいなので、想像以上に浸透しています。また、単に利用者が多いというだけでなく、「データアナリストには遠慮して頼めなかったけどSocratesになら何でも聞ける」というように、AIを活用したツールならではの効果が得られているのも興味深いです。

ー新しいツールの社内浸透に悩む人は多いと思いますが、それだけスムーズに広がった要因は何が考えられますか?
kobaken:構想段階からSocratesの目指す状態を「master doc」として言語化し、それをチームや関係するステークホルダーに公開して意見を募っていたことが大きいです。ポジティブな意見もネガティブな意見も集まりましたが、Socratesに本当に必要な機能を見極める上でとても重要でした。また、リリースと同時に社内全体に広報し、「ちょっと試した」利用者によるログを収集できた点も大きかったです。最初はコアな機能しかなかったので「まだこんなものか」というフィードバックもありましたが、高頻度に機能追加や改善のリリースを繰り返すことで、「もうここまで出来るようになったのか」と着々とファンを増やしていけました。
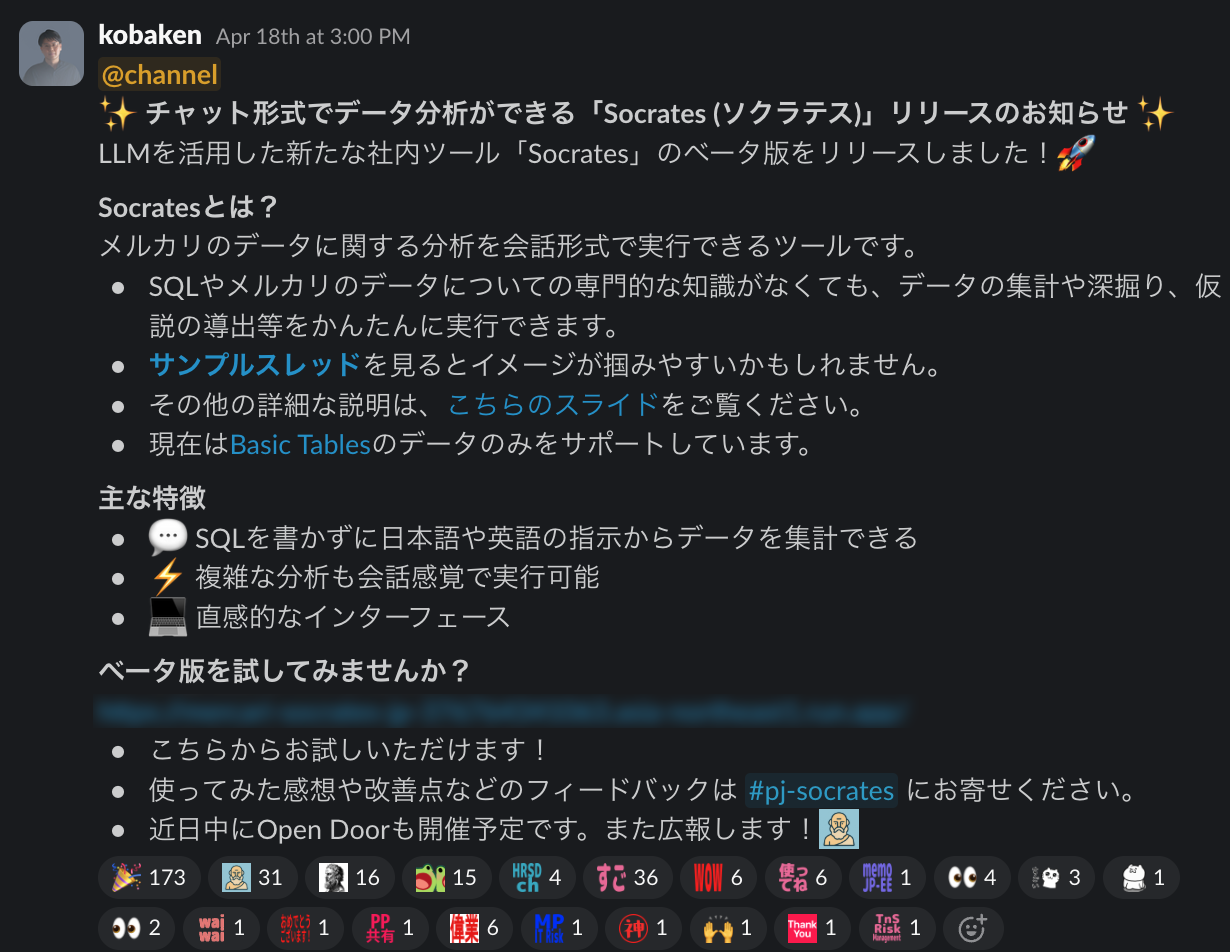
Shuichi:ローンチ後は、毎週利用状況をウォッチして、利用回数の多い“ヘビーユーザー”を見つけるようにしています。彼らから集中的にフィードバックをもらったり、新機能を先に試してもらったりしながら、改善を進めています。一方で、経営陣など浸透のキーマンになる人を定めて、その人たちに自然に使ってもらうにはどうしたらいいかということも考えています。
ー社内ツールでありながら、外部向けプロダクトをローンチするかのようなコミュニケーションや浸透施策を進めた結果、素早く広まったということですね。
データ整備の鍵は、メタデータ付与とテーブル設計
ー少し話を広げて、開発や組織運営についても深掘りしていきたいと思います。まずは、データ整備について。Socratesは「Basic Tables」をインプットしていますが、人間が処理する場合と、AIが処理する場合にデータ整備のやり方に違いはありますか?
kobaken:AIに精度の高いクエリをつくってもらうには、データに対するメタデータの付与がポイントになります。これまではデータアナリストのように一定程度データに詳しい利用者が中心だったため、先ほどのBasic Tablesについてもスプレッドシートにメタデータを記述する程度で充分でした。でもSocratesを経由すると、データアナリストほどデータの仕様に詳しくない従業員もデータを参照することになるので、たとえばBigQuery上にカラム(列)の説明文をしっかり書いてあげる等、よりLLMフレンドリーに、LLMがより安定して高品質な出力を生成するための工夫が重要になってきます。
ー今後はBasic TablesをAI側に合わせていく方針なのでしょうか?
na0:人間側の使いやすさを犠牲にしてまで、Socratesに最適化したデータをつくろうとは思っていません。ただ、Socratesを含むAI向けのインタフェースを用意する可能性はあります。両者が使いやすいうまいバランスを実現していきたいと思っています。
ー人間もAIもエンパワーメントできるようなデータ整備のあり方は各社模索しているところだと思います。メルカリなりの答えが出るのが楽しみですね。

Socrates導入は出発点。経営、組織、働き方もAIを前提に
ー今後のSocratesの展望や課題についてもお聞きしたいです。
kobaken:プロダクトで収集しているデータだけを対象にした分析を超えて、その背後にある事象を踏まえた分析や、仮説の提案まで実行できるようにしていきたいです。具体的には、プロダクトでの機能リリースやキャンペーンのカレンダー等、ビジネスメタデータのような情報も加味した分析を可能にし、より広範な問いをサポートできるようにしたいです。
また、利用者層も広げていきたいですね。今のユーザー層はPdMやデータアナリストが中心ですが、マーケターや経営層などにも使ってもらえるようにする。
ー今後、ボトルネックになりそうなことはありますか?
kobaken:インプットするデータを無闇に増やすと、それがノイズとなってアウトプットの質を下げてしまう可能性があります。参照すべきデータの優先順位や集計定義を定めるなどして、品質と利便性のバランスをコントロールしていく必要はありますね。また、利用者の増加により、ツールへの要望も多種多様になってきているので、全体最適を考えながら成長戦略を描いていきたいです。
ーBI Productチームの組織的な展望はいかがですか?
kobaken:Socratesの浸透につれて、Socrates以前の世界とは課題発見や解決のアプローチが大きく変わってきたと感じています。たとえば以前は、データ利用者が抱えている課題に関する相談や依頼をトリガーにチームの活動が決まることも多かったですが、Socratesの賢さや手の届く範囲が増えるほど、それらの課題は顕在化しづらくなると考えています。具体的には、これまでよく発生していた「クエリのパフォーマンスが悪いから中間テーブルを作ろう」という議論は起こりづらくなると思っています。
より広い視野で課題を見つけ、組織を横断するインパクトをもたらせるようになるという点で、それぞれのメンバーの裁量はすごく大きくなるはずです。マネージャーとしては、彼らの活動が組織に与えるインパクトが最大化されるように、適切にリスクを評価・受容しながらチームを運営していきたいです。
ーAIの技術的進化に対応できるような開発体制のつくりかたは、どの会社も模索していますよね。
Shuichi:「これは開発だからエンジニアに頼む」ではなく「BIチームで内製できるからやってしまおう」みたいに、柔軟な役割分担ができるといいですよね。こうしてAI活用が進むにつれて、ジョブの定義や、そこから逆算された採用基準なども変わっていくと思います。最終的に人がやるのは、インプットするデータを整備する「入口」と、施策を実行したり責任をとったりする「出口」だけかもしれません。

ーそうした変化を踏まえて、AIに対応した経営についても、議論が進んでいくことを期待したいです。
Shuichi:たとえば、会社が4半期ずつ方針を決めるサイクルだと、技術的変化に追いつけない可能性もあります。Socrates開発は、Geminiのアップデートを機に本格始動しましたが、期初には予測できていなかった。現場の責任者の判断でスパッと方針を変えるような仕組みや体制がないと、技術に追いつくのはより難しくなっていくと思います。
kobaken:そうした組織体制や経営のアップデートについても視野に入れながら、Socratesが事業の成長により貢献していくための改善を進めていきたいです。

文:佐藤 史紹 写真:タケシタ トモヒロ
この記事に関連する求人情報
募集中の求人の一部をご紹介します
-
Information Security Engineer – US App
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Research Scientist, AR & Spatial Computing – Mercari
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Business Development Manager – Mercari Marketplace
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Software Engineer, iOS (Platform Product) – Merpay
オフィス: 東京・六本木オフィス
会社・事業: メルペイ
-
Software Engineer, iOS (Credit) – Merpay
オフィス: 東京・六本木オフィス
会社・事業: メルペイ
-
Growth Data Scientist, US App
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Global Campaign Specialist – Mercari Marketplace
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Global Campaign Specialist – Mercari Marketplace
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Senior Technical Project Manager (Corporate DX) – Mercari
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Lead of UA Strategy, US App
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
別サイトに移動します
Share
この記事に関連する求人情報
募集中の求人の一部をご紹介します
-
Information Security Engineer – US App
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Research Scientist, AR & Spatial Computing – Mercari
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Business Development Manager – Mercari Marketplace
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Software Engineer, iOS (Platform Product) – Merpay
オフィス: 東京・六本木オフィス
会社・事業: メルペイ
-
Software Engineer, iOS (Credit) – Merpay
オフィス: 東京・六本木オフィス
会社・事業: メルペイ
-
Growth Data Scientist, US App
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Global Campaign Specialist – Mercari Marketplace
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Global Campaign Specialist – Mercari Marketplace
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Senior Technical Project Manager (Corporate DX) – Mercari
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
-
Lead of UA Strategy, US App
オフィス: 東京・六本木オフィス
会社・事業: メルカリ
別サイトに移動します


